о рекурсивных моделях
Jan. 7th, 2026 01:28 am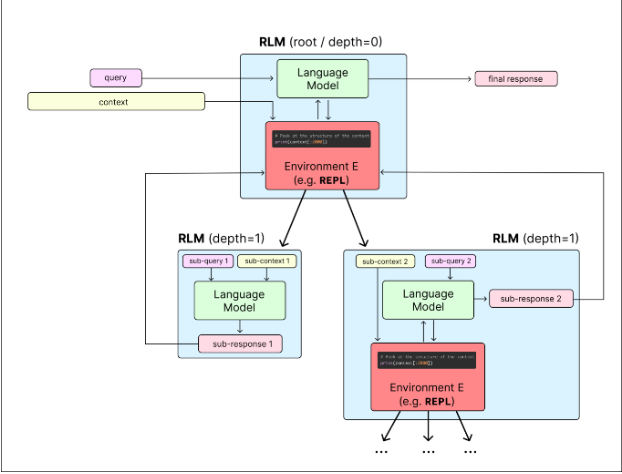
Новая статья "Recursive Language Models" (Zhang, Kraska, Khattab) описывает интересный трюк с LLMами, помогающий выжать из них хорошее поведение на очень длинном контексте - мегабайты текста или больше.
Сегодняшние модели, даже если они поддерживают очень широкое окно контекста, и им можно скормить, скажем, "Войну и мир" за один раз, затрудняются с выполнением сложных заданий на таком тексте. Если попросить что-то вроде "сделать список всех диалогов в тексте, для каждого указать имена персонажей-участников", у них не хватает "сфокусированного внимания".
Идея "рекурсивных моделей" следующая. Мы даем модели доступ к REPL (среде, где она может давать простые команды на Питоне, которые сразу выполняются), и весь ввод - например, текст романа или что угодно - заложен в переменную внутри этого контекста. Модель может разбить его на части с помощью простых кусков кода (скажем, на главы поиском слов "Chapter [Number]"), каждую часть дать самой себе уже в виде настоящего ввода - это и есть рекурсивный вызов - а результаты рекурсивных вызовов объединить. При этом модель-планировщик ни разу не видит весь текст целиком в качестве ввода, и поэтому не путается. А главное - конкретную стратегию того, как разбить задачу на части и вызывать себя рекурсивно модель придумывает каждый раз сама. Мы всего лишь даем ей доступ к REPL и к рекурсивным вызовам и объясняем в промпте, что она может этим пользоваться.
В статье дается несколько разных примеров задач, на которых этот прием дает гораздо лучшие результаты (на больших вводах), чем лучшие модели сейчас. У меня есть определенные сомнения в том, насколько широко это можно растянуть. Но идея несомненно полезная, и дает улучшение моделей по сути "бесплатно", по крайней мере там, где работает.